Python 垃圾回收
垃圾回收(Garbage Collection,GC)是 Python 自带的机制,用于自动释放不会再用到的内存空间。在实现上,以 引用计数 机制为主,以 标记清除 和 分代收集 两种算法为辅。
必要时可使用 objgraph 可视化分析工具,定位内存泄露。
函数的参数传递机制
当调用函数时,基本的参数传递机制有三种形式:值传递、指针传递、引用传递。
值传递(pass by value):形参是实参的拷贝,会作为局部变量额外申请内存空间,改变形参的值并不会影响外部实参的值。
指针传递(pass by pointer):形参为指向实参地址的指针,当对形参的指向进行操作时,就相当于对实参本身进行操作。(C、C++ 专属)
引用传递(pass by reference):形参相当于是实参的“别名”,实际传递的还是对象地址,对形参的操作其实就是对实参的操作。
Python 的对象引用
在 Python 中函数传递参数时 既非传值也不是传引用,而是采用 对象引用传递(pass by object reference) 的方式。实际上,这种方式相当于传值和传引用的一种综合——当函数参数为可变对象时,传递的是引用;当函数参数为不可变对象时,传递的是值。
不可变对象(Immutable Object):长度大小固定,无法增加删除或者改变元素,如 数值 Int / Float、字符串 String、元组 Tuple
可变对象(Mutable Object):长度大小不固定,可以随意地增加删除或者改变元素,如 列表 List、字典 Dict、集合 Set
示例:对象引用练习
1 | |
对象的赋值和拷贝
浅拷贝(shallow copy):重新分配一块内存,创建一个新的对象,其中的元素是原对象中子对象的引用。
深拷贝(deep copy):重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没有任何关联。
==操作符比较对象之间的值是否相等;is操作符比较对象的身份标识是否相等,即它们是否为同一个对象,是否指向同一个内存地址;
使用id(object)方法,获得一个对象的身份标识(在内存中唯一)。
示例一:创建浅拷贝
1 | |
在浅拷贝中,如果原对象中的元素不可变,那倒无所谓;但如果元素可变,浅拷贝通常会带来一些副作用,尤其需要注意。
示例二:浅拷贝的副作用
1 | |
如果想避免浅拷贝的副作用,完整地拷贝一个对象,可以使用深度拷贝。另外,深度拷贝中会维护一个字典,记录已经拷贝的对象及其 ID,来提高效率并防止无限递归的发生。
示例三:创建深拷贝
1 | |
示例四:无限嵌套列表
1 | |
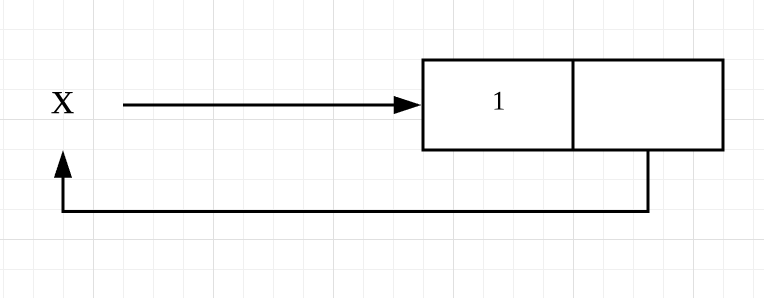
题目一中,x 指向一个列表,列表的第一个元素为 1。执行了 append 操作后,第二个元素又反过来指向 x,即指向了 x 所指向的列表,因此形成了一个无限嵌套的循环:[1, [1, [1, [1, …]]]]。不过,虽然 x 是无限嵌套的列表,但 x.append(x) 的操作,并不会递归遍历其中的每一个元素。它只是扩充了原列表的第二个元素,并将其指向 x,因此不会出现 stack overflow 的问题。虽然 x 是无限嵌套的列表,但 x 实际只有 2 个元素组成,第一个元素为 1,第二个元素为指向自身的列表,因此 len(x) 返回 2。
题目二中,x 是一个无限嵌套的列表,y 是 x 的深度拷贝,按道理来讲 x == y 应该是为 True 的。但使用比较操作符 “==” 进行比较的时候,“==” 操作符会递归地遍历对象的所有值,并逐一比较。此时,因为 x、y 是无限嵌套列表,当达到递归深度时程序便会抛出 RecursionError 异常。
del 语句和引用计数
为了简化内存管理,Python 通过 引用计数 机制实现自动垃圾回收功能。Python 中的每个对象都有一个对应的引用计数,用来记录该对象在不同场所分别被引用了多少次。每引用一次对象,相应的引用计数就会加 1,每销毁一次对象,则相应的引用就会减 1。
执行 del 语句 可以删除对象的引用(不会删除对象),使对象的引用计数减少。当对象的引用计数为 0 时,Python 内部的自动垃圾回收机制(GC)会将此对象所占用的内存收回,此时才真正从内存中删除这个对象。
使用
sys.getrefcount(object)方法,获得一个对象的引用计数。(此函数调用时会增加一次引用计数)
示例:释放循环引用的对象
1 | |
标记清除和分代收集
Python 使用 标记清除算法(mark-sweep) 和 分代收集算法(generational),来启用针对循环引用的自动垃圾回收。
标记清除
我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。
当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。
分代收集
Python 将所有对象分为三代。刚刚创立的对象是第 0 代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。
分代收集基于的思想是:新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高 Python 的性能。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!